All demos on this page are at 1x real time.
Demo on Mandarin question answering.
Demo on English question answering.
Demo on prompt following and role play.
Freeze-Omni is a speech-to-speech dialogue model, exhibiting
the characteristic of being "smart" as it is constructed upon a "frozen" text-modality LLM.
This enables it to keep the original intelligence of the LLM backbone, without being affected by the forgetting
problem induced by the fine-tuning process for integration of the speech modality. Specifically,
Freeze-Omni contains a speech encoder that supports streaming speech input and a speech decoder
that generates streaming output speech. Three key strategies are adopted to implement the speech-to-speech dialogue system:
Chunk-wise Streaming Input. Freeze-Omni has a speech encoder supporting chunk-wise streaming input speech features to obtain a fast response to input.
A 3-stage training strategy can help it keep strong acoustic robustness.
AR-base Speech Output. Freeze-Omni has an AR speech decoder based on a single codebook, which can achieve low-latency speech output in streaming.
A prefix tuning method is used so that training on only a small amount of Q&A data can achieve the ability to produce high-quality speech synthesis.
Chunk-level State Prediction. Freeze-Omni adds a classification layer after the last layer of the backbone LLM to predict different states.
These states will determine whether or not the user interrupts the dialogue to achieve a duplex dialogue for the user and the bot.
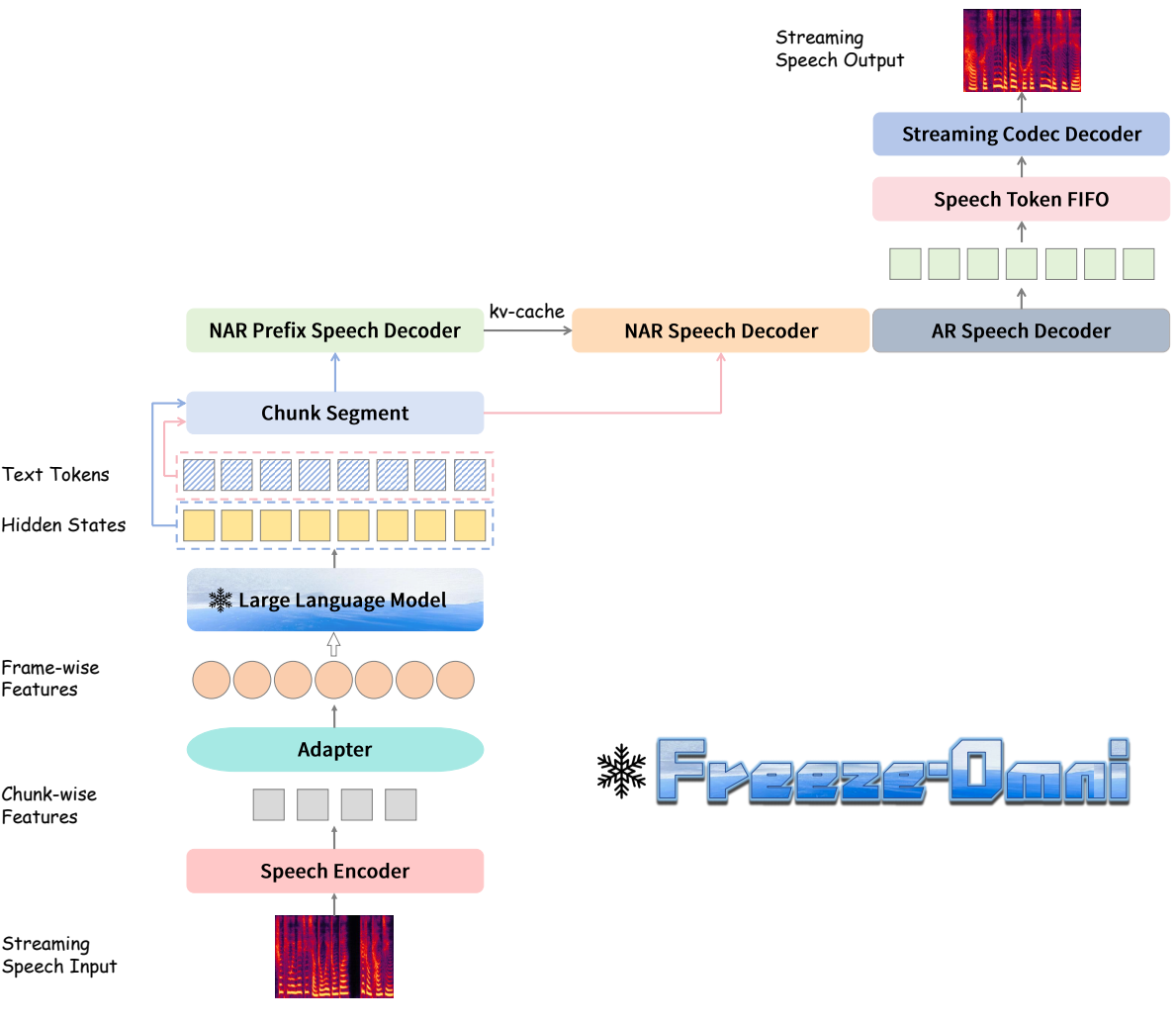
Besides we implement a Model as a Server strategy. We first started several models simultaneously and regarded them as a server. Then, when a user's VAD was triggered, the speech would be sent to the server in the form of chunks, and the server would be responsible for scheduling which idle model should respond to the current chunk. Since we separated all the kv-cache and CNN cache of the speech encoder and LLM during the inference process, the server only needs to save the inference cache for each user. In this way, any model in the server could respond to any chunk of any user, and there was no need to specify which model was used as a monitor or a generator.
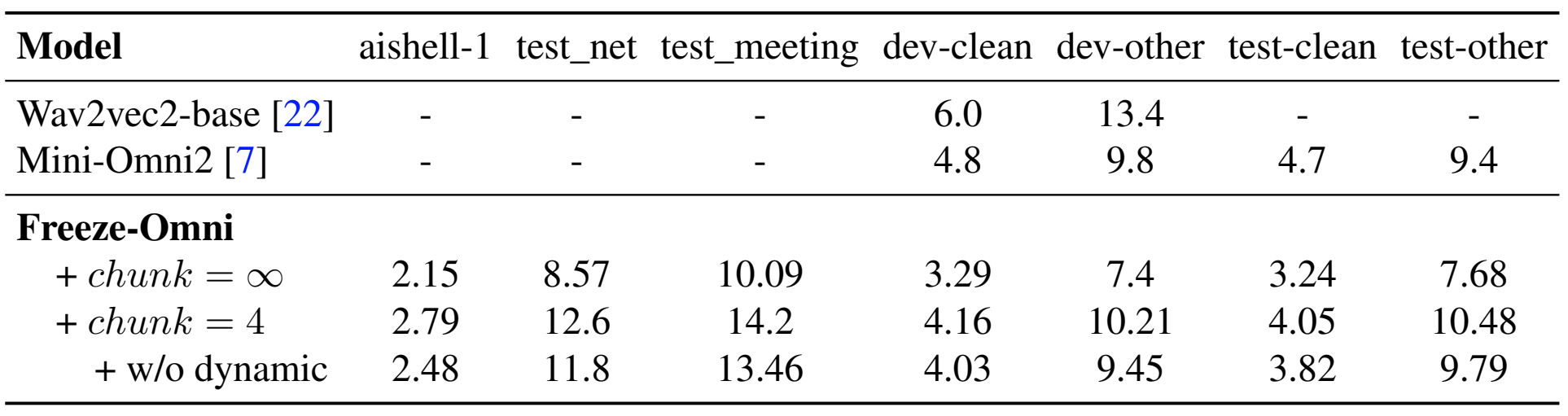
Evaluation of speech understanding through ASR tasks, using CER(%) and WER(%).
Evaluation of output speech quality on different top-k of AR decoder by using CER(%).

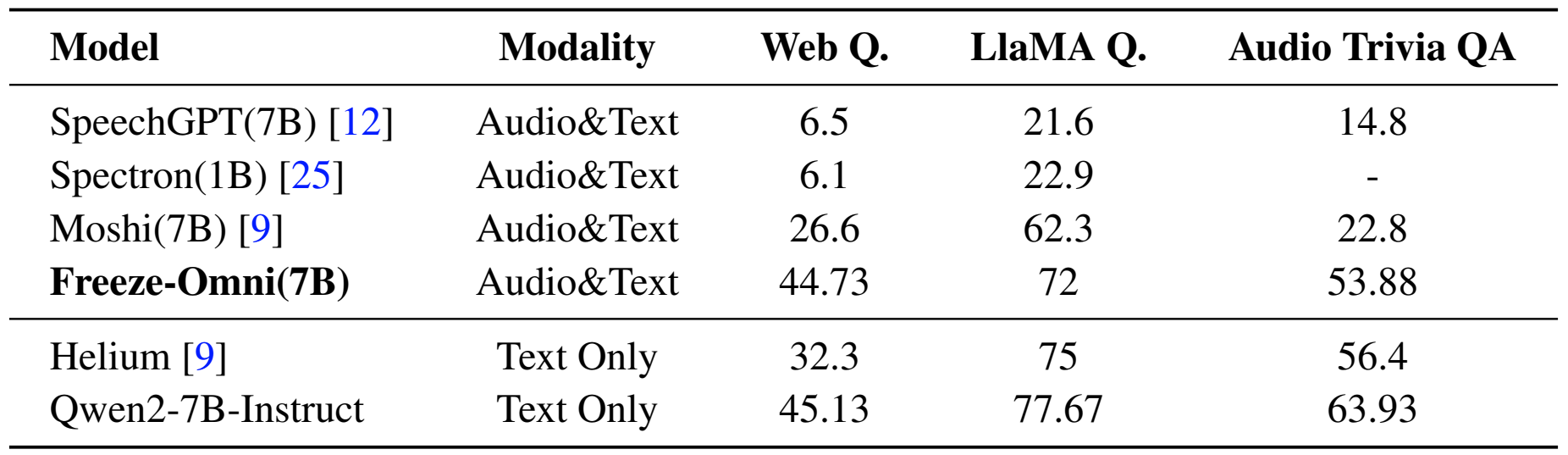
Evaluation of spoken question answering on accuracy(%).
Analysis of end-to-end latency for different parts.

@article{xiong2024freeze,
title={Freeze-Omni: A Smart and Low Latency Speech-to-speech Dialogue Model with Frozen LLM},
author={Xiong Wang and Yangze Li and Chaoyou Fu and Lei Xie and Ke Li and Xing Sun and Long Ma},
journal={arXiv preprint arXiv:2411.00774},
year={2024}
}